plot(exampleA1B1A2B2_zvt)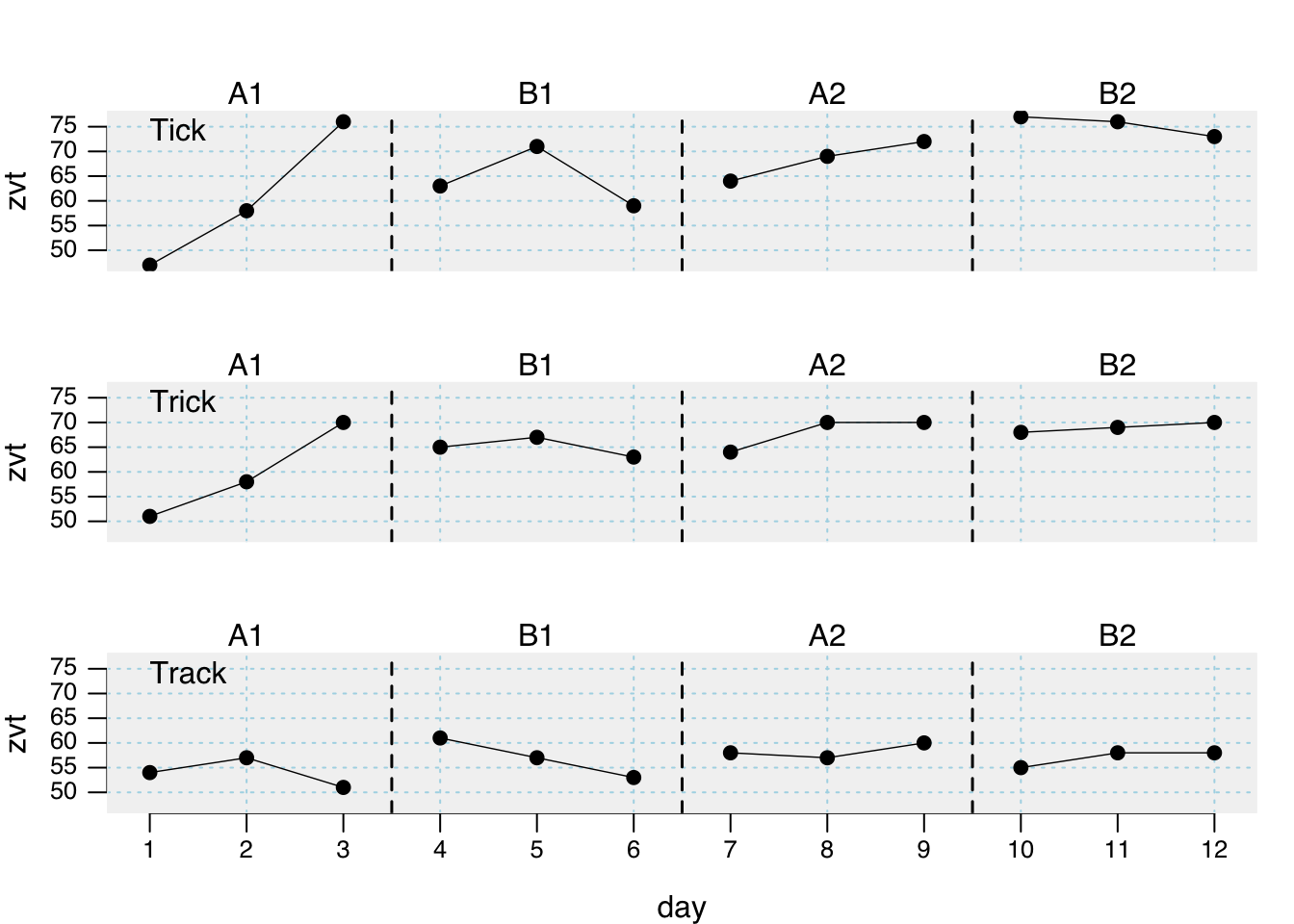
plotSC plotting functionplotSC(
data,
dvar,
pvar,
mvar,
ylim = NULL,
xlim = NULL,
xinc = 1,
lines = NULL,
marks = NULL,
xlab = NULL,
ylab = NULL,
main = ““,
case.names = NULL,
style = getOption(”scan.plot.style”),
…
)
After you build an scdf the plot command helps to visualize the data. When the scdf includes more than one case a multiple baseline figure is provided. Various arguments can be set to customize the appearance of the plot. Table D.1 gives an overview of all available arguments.
plot(exampleA1B1A2B2_zvt)
Labels of the axes and for the phases can be changed with the xlab, ylab, and the phase.names arguments. The x- and y-scaling of the graphs are by default calculated as the minimum and the maximum of all included single cases. The xlim and the ylim argument are used to set specific values. The argument takes a vector of two numbers. The first for the lower and the second for the upper limit of the scale. In case of multiple single cases an NA sets the individual minimum or maximum for each case. Assume for example the study contains three single cases ylim = c(0, NA) will set the lower limit for all three single cases to 0 and the upper limit individually at the maximum of each case. The argument xinc sets the incremental steps for the x-axis ticks with corresponding values. For example xinc = 1 will set a tick for every measurement time increase of 1 while xinc = 5 will only set every ffith tick.
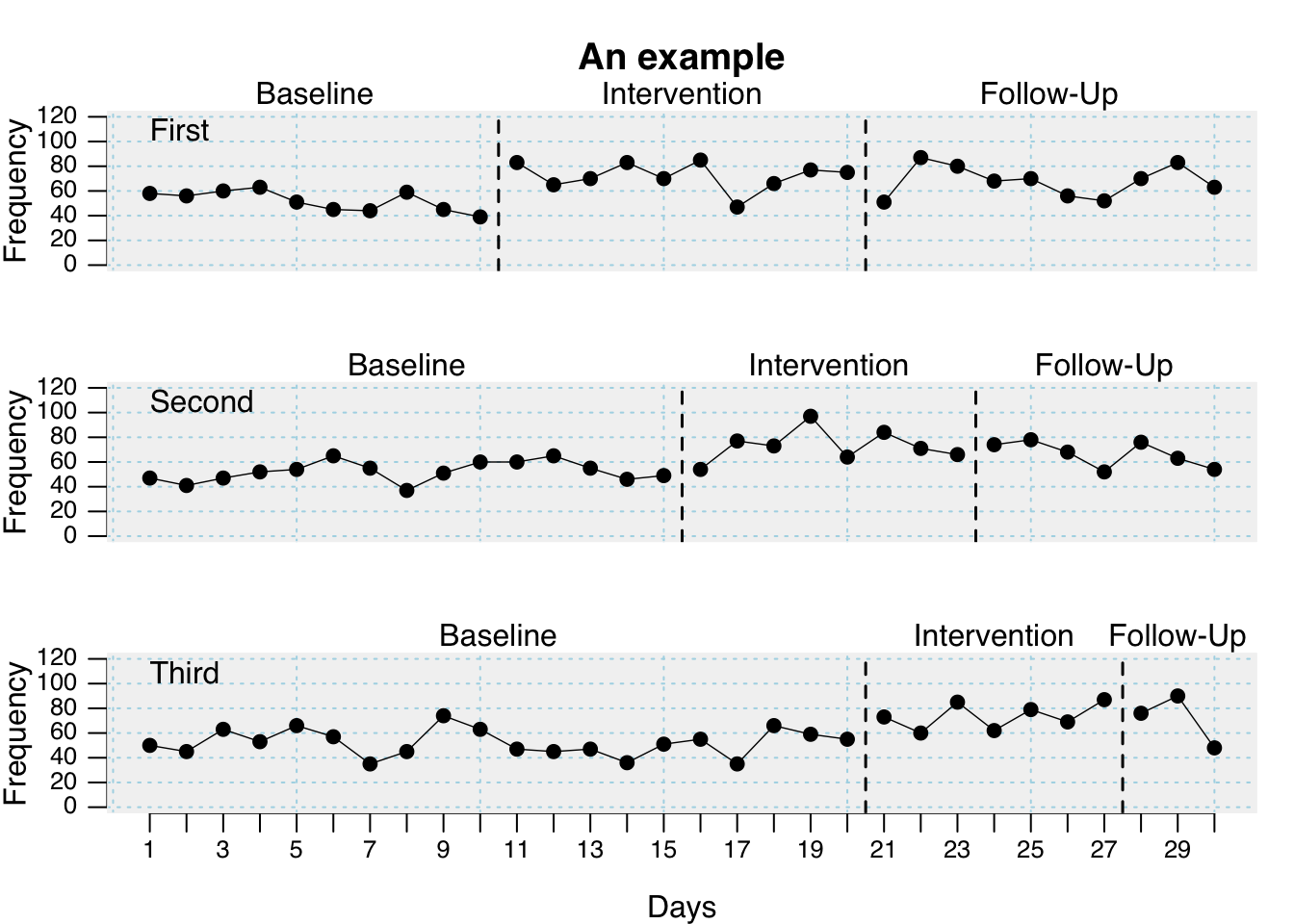
plot(
exampleABC,
phase.names = c("Baseline", "Intervention", "Follow-Up"),
case.names = c("First", "Second", "Third"),
ylab = "Frequency",
xlab = "Days",
main = "An example",
ylim = c(0, 120),
xinc = 2
)
| Argument | What it does ... |
|---|---|
| data | A single-case data frame. |
| ylim | Lower and upper limits of the y-axis |
| xlim | Lower and upper limits of the x-axis. |
| style | A specific design for displaying the plot. |
| lines | A character or list defining one or more lines or curves to be plotted. |
| marks | A list of parameters defining markings of certain data points. |
| main | A figure title |
| phase.names | By default phases are labeled as given in the phase variable. Use this argument to specify different labels: `phase.names = c('Baseline', 'Intervention')`. |
| case.names | Case names. If not provided, names are taken from the scdf or left blank if the scdf does not contain case names. |
| xlab | The label of the x-axis. The default is taken from the name of the measurement variable as provided by the scdf. |
| ylab | The labels of the y-axis. The default is taken from the name of the dependent variable as provided by the scdf. |
| xinc | An integer. Increment of the x-axis. 1 : each mt value will be printed, 2 : every other value, 3 : every third values etc. |
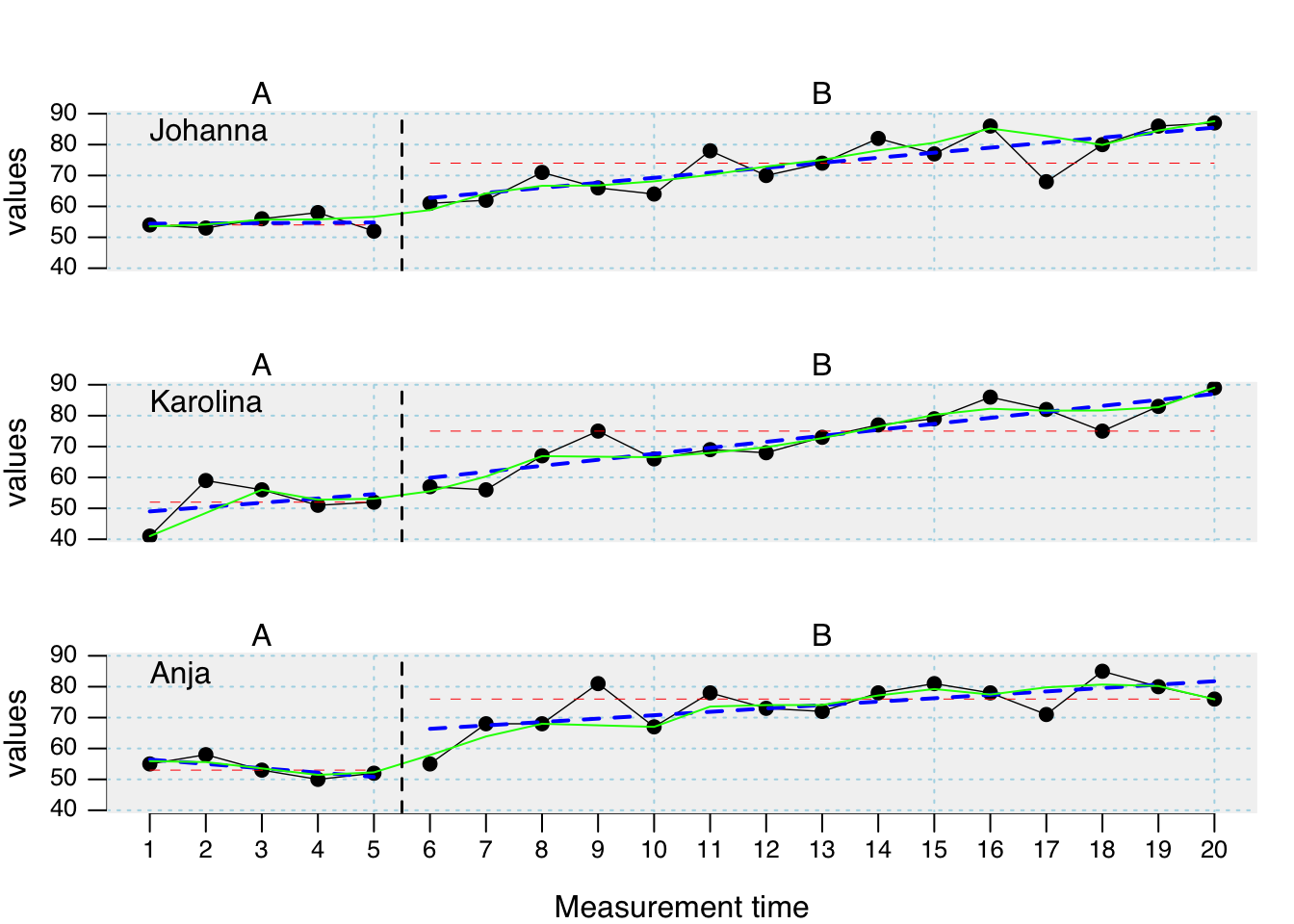
Extra lines can be added to the plot using the lines argument. The lines argument takes several separate sub-arguments which have to be provided in a list. In its most simple form this list contains one element. lines = list(type = 'median') adds a line with the median of each phase to the plot. Additional arguments like col or lwd help to format these lines. For adding red thick median lines use the command lines = list(type = 'median', col = 'red', lwd = '2').
| Argument | What it does ... |
|---|---|
| median | separate lines for the medians of each phase |
| mean | separate lines for the means of each phase. By default it is 10%-trimmed. Other trims can be set using a second parameter (e.g., `lines = list(type = 'mean', trim = 0.2)` draws a 20%-trimmed mean line). |
| trend | Separate lines for the trend of each phase. |
| trendA | Trend line for phase A, extrapolated throughout the other phases |
| maxA | Line at the level of the highest phase A score. |
| minA | Line at the level of the lowest phase A score. |
| medianA | Line at the phase A median score. |
| meanA | Line at the phase A 10%-trimmed mean score. Apply a different trim, by using the additional argument (e.g., `lines = list(type = 'meanA', trim = 0.2)`). |
| movingMean | Draws a moving mean curve, with a specified lag: `lines = list(type = 'movingMean', lag = 2)`. Default is a lag 1 curve. |
| movingMedian | Draws a moving median curve, with a specified lag: `lines = list(type = 'movingMedian', lag = 3).` Default is a lag 1 curve. |
| loreg | Draws a non-parametric local regression line. The proportion of data influencing each data point can be specified using `lines = list(type = 'loreg', f = 0.66)`. The default is 0.5. |
| lty | Line type. Examples are: 'solid','dashed', 'dotted'. |
| lwd | Line thickness, e.g., `lwd = 4`. |
| col | Line colour, e.g., `col = 'red'`. |
plot(
exampleAB,
lines = list(
list(type = "median", col = "red", lwd = 0.5),
list(type = "trend", col = "blue", lty = "dashed", lwd = 2),
list(type = "loreg", f = 0.2, col = "green", lty = "solid", lwd = 1)
)
)
Specific data points can be highlighted using the marks argument. A list defines the measurement times to be marked, the marking color and the size of the marking. marks = list(position = c(1,5,6)) marks the first, fifth, and sixth measurement time. If the scdf contains more than one data-set marking would be the same for all data sets in this example. In case you define a list Containing vectors, marking can be individually defined for each data set. Assume, for example, we have an scdf comprising three data sets, then marks = list(position = list(c(1,2), c(3,4), c(5,6))) will highlight measurement times one and two for the first data set, three and four for the second and five and six for the third. pch, col and cex define symbol, colour and size of the markings.
# plot with marks in a red circles 2.5 times larger than the standard symbol
# size. exampleAB is an example scdf included in the scan package
marks <- list(
positions = list( c(8, 9), c(17, 19), c(7, 18) ),
col = 'red', cex = 2.5, pch = 1
)
plot(exampleAB, marks = marks, style = "sienna")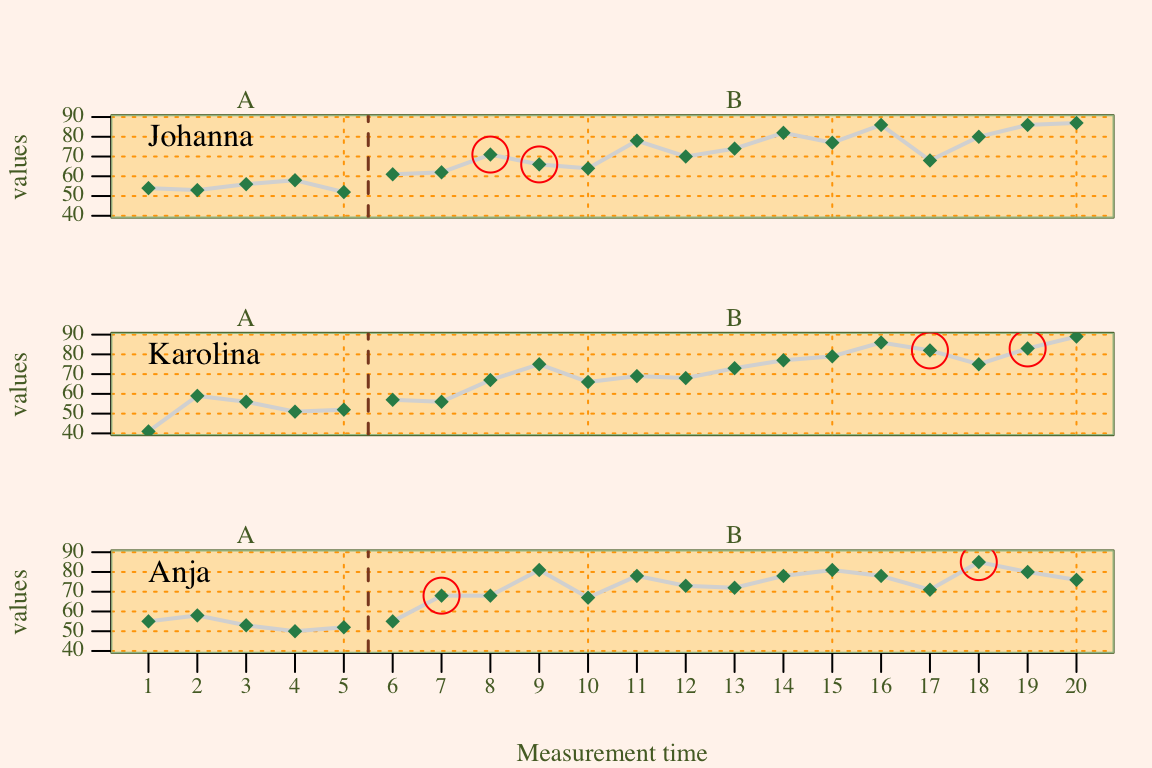
style_plot(style = “default”, …)
The style argument of the plot function allows to specify a specific design of a plot. By default, the grid style is applied. scan includes some further predefined styles. default, yaxis, tiny, small, big, chart, ridge, annotate, grid, grid2, dark, nodot, and sienna. The name of a style is provided as a character string (e.g., style = "grid").
Some styles only address specific elements (e.g., “small” or “tiny” just influence text and line sizes). These styles lend themselves to be combined with other styles. This could be achieved by providing several style names to the plot argument: style = c("grid", "annotate", "small"). A style overwrites the settings of all previously included style.
Beyond predefined styles, styles can be individually modified and created. New styles are provided as a list of several design parameters that are passed to the style argument of the plot function. Table D.3 shows all design parameter that could be defined.
To define a new style, first create a list containing a plain design. The style_plot function returns such a list with the default values for a plain design (e.g., mystyle <- style_plot()). Single design parameters can now be set by assigning a specific value within the list. For example, newstyle$fill <- "grey90" will set the fill parameter to "grey90". Alternatively, changes to the plain design can already by defined within the style_plot function. To set a light-blue background color and also an orange grid, create the style style_plot(fill.bg = "lightblue", grid = "orange"). If you do not want to start with the plain design but a different of the predefined styles, set the style argument. If, for example, you like to have the grid combined with the big style but want to change the color of the grid to orange type style_plot(style = c("grid", "big"), col.grid = "orange"). plot(mydata, style = mystyle) will apply the new style in a plot. Please note that the new style is not passed in quotation marks.
| Argument | What it does ... |
|---|---|
| fill | If TRUE area under the line is filled. |
| col.fill | Sets the color of the area under the line. |
| grid | If TRUE a grid is included. |
| col.grid | Sets the color of the grid. |
| lty.grid | Sets the line type of the grid. |
| lwd.grid | Sets the line thikness of the grid. |
| fill.bg | If not NA the backgorund of the plot is filled with the given color. If multiple colours are provided, the colours change with phases (e.g., `fill.bg = c('aliceblue', 'mistyrose1', 'honeydew')` |
| annotations | A list of parameters defining annotations to each data point. This adds the score of each MT to your plot. `'pos'` Position of the annotations: 1 = below, 2 = left, 3 = above, 4 = right. `'col'` Color of the annotations. `'cex'` Size of the annotations. `'round'` rounds the values to the specified decimal. `annotations = list(pos = 3, col = 'brown', round = 1)` adds scores rounded to one decimal above the data point in brown color to the plot. |
| text.ABlag | By default a vertical line separates phases A and B in the plot. Alternatively, you could print a character string between the two phases using this argument: `text.ABlag = 'Start'`. |
| lwd | Width of the plot line. Default is `lwd = 2`. |
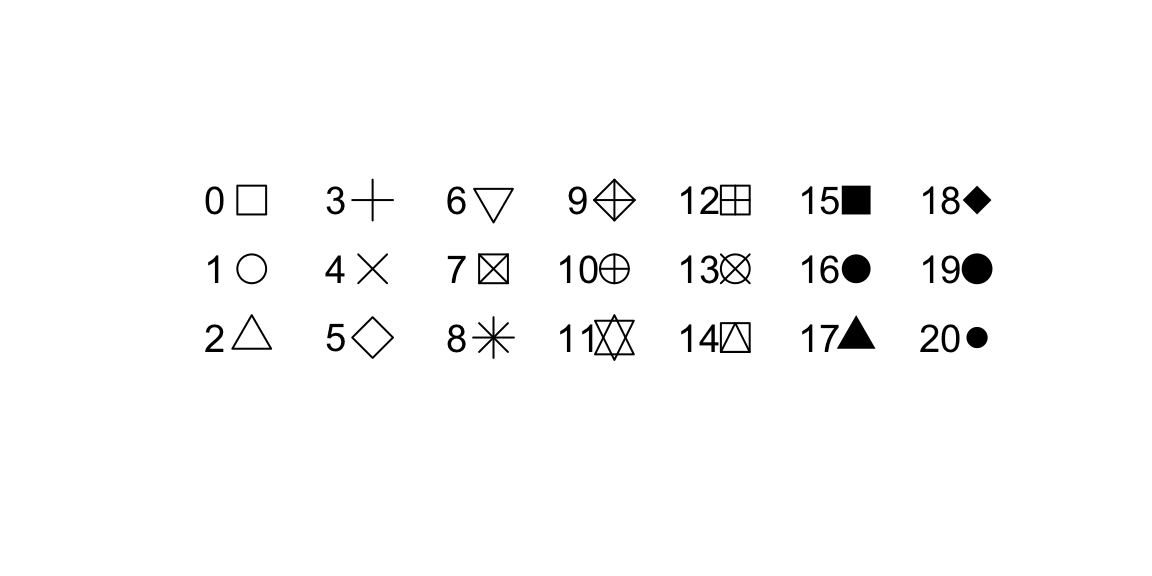
| pch | Point type. Default is `pch = 17` (triangles). Other options are for example: 16 (filled circles) or 'A' (uses the letter A). |
| col.lines | The color of the lines. If set to an empty string no lines are drawn. |
| col.dots | The color of the dots. If set to an empty string no dots are drawn. |
| mai | Sets the margins of the plot. |
| ... | Further arguments passed to the plot command. |
The width of the lines are set with the lwd argument, col is used to set the line colour and pch sets the symbol for a data point. The pch argument can take several values for defining the symbol in which data points are plotted.
Here is an example customizing a plot with several additional graphic parameters
newstyle <- style_plot(
fill = "grey95",
fill.bg = c('aliceblue', 'mistyrose1', 'honeydew'),
names = list(col = "brown", cex = 2, font = 3, side = 3),
annotations = list(col = "brown"),
col.dots = "blue",
grid = "lightblue",
pch = 16)
plot(exampleABAB, style = newstyle)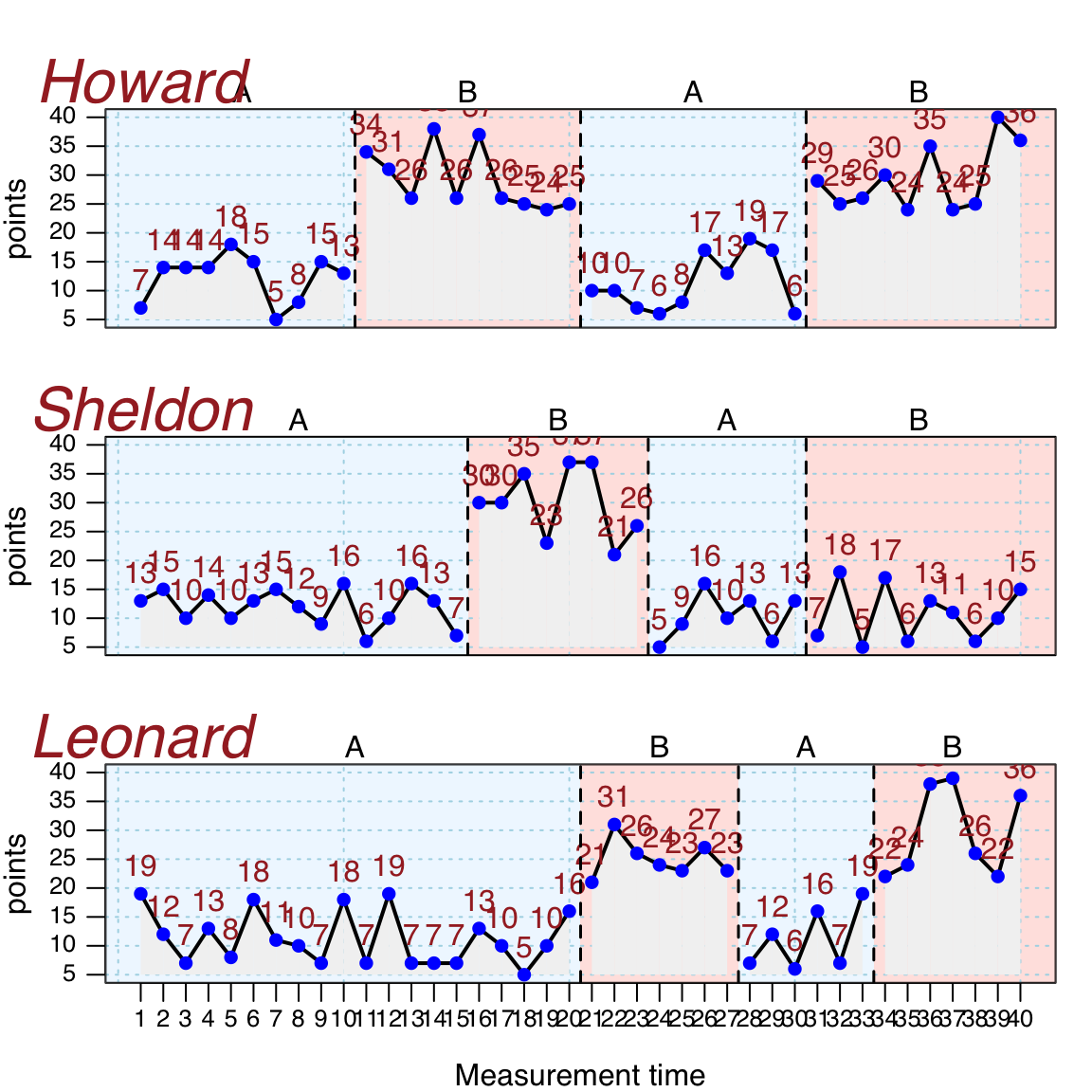
smooth_cases(data, dvar, mvar, method = “mean”, intensity = NULL, FUN = NULL)
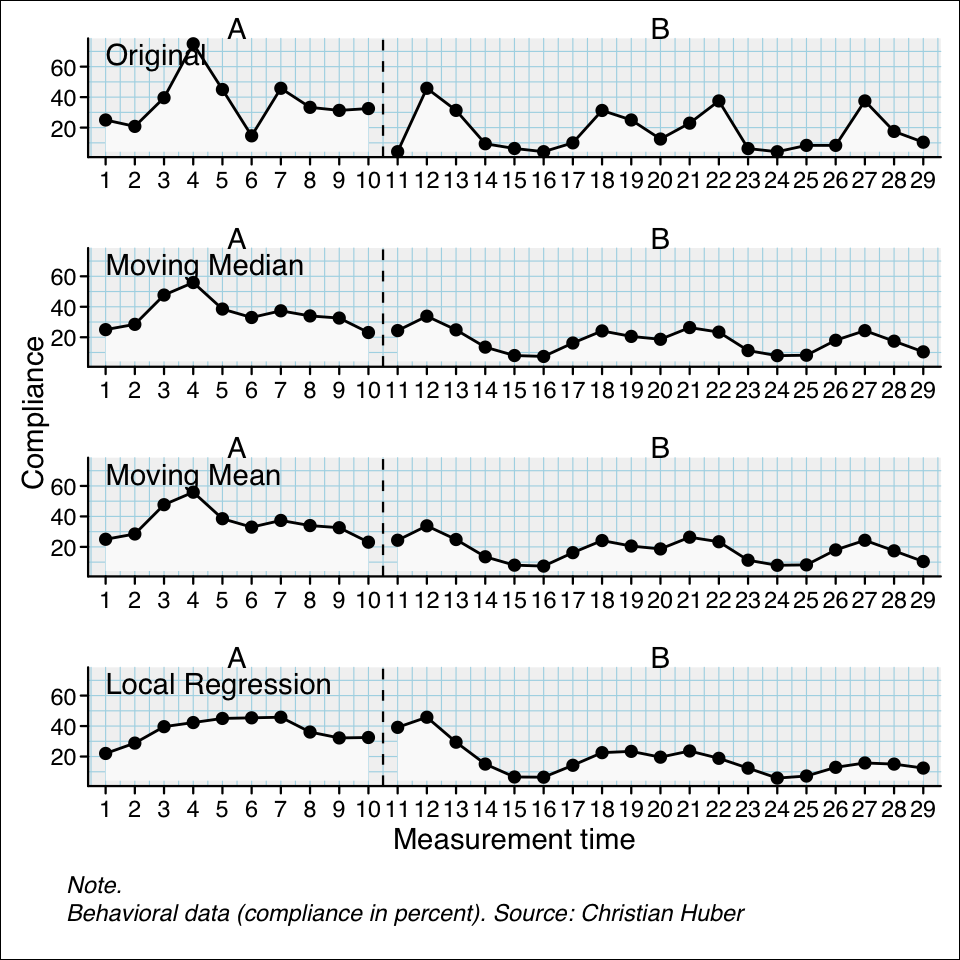
The smooth_cases function provides procedures to smooth single-case data and eliminate noise. A moving average function (mean- or median-based) replaces each data point by the average of the surrounding data points step-by-step. A lag defines the number of measurements before and after the calculation is based on. So a lag-1 will take the average of the proceeding and following value and lag-2 the average of the two proceeding and two following measurements. With a local regression function, each data point is regressed by its surrounding data points. Here, the proportion of measurements surrounding a value is usually defined. So an intensity of 0.2 will take the surrounding 20% of data as the basis for a regression.
The function returns am scdf with smoothed data points.
## Use the three different smoothing functions and compare the results
berta_mmd <- smooth_cases(Huber2014$Berta)
berta_mmn <- smooth_cases(Huber2014$Berta, FUN = "movingMean")
berta_lre <- smooth_cases(Huber2014$Berta, FUN = "localRegression")
new_study <- c(Huber2014$Berta, berta_mmd, berta_mmn, berta_lre)
names(new_study) <- c("Original", "Moving Median", "Moving Mean", "Local Regression")
plot(new_study, style = "grid2")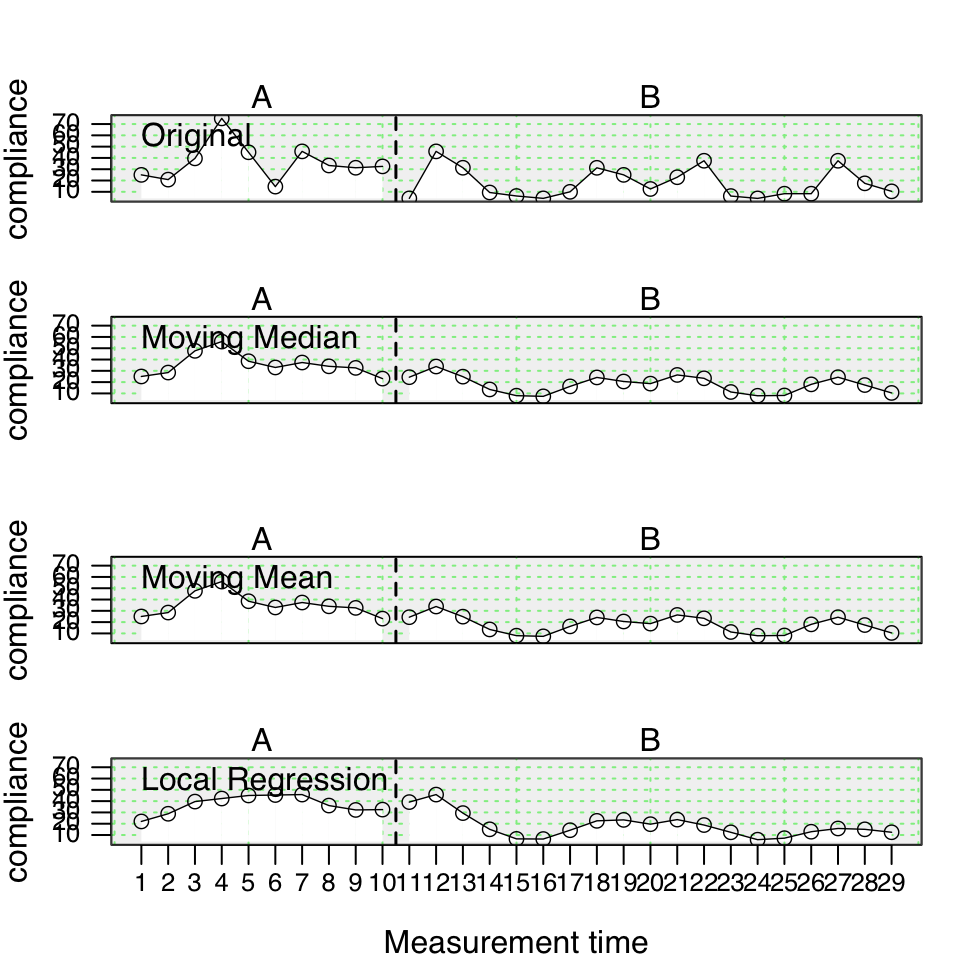
Here is the syntax for the upcoming scplot() function (see Chapter 5):
scplot(new_study) |> add_ridge()